[Last Updated: May 4, 2020]
This tutorial will introduce you to the Python programming language and how it can be used for basic text analysis.
No programming experience is necessary.
1) Start a new Trinket project
1.1) You can either use the embedded trinket on the right side of this page
or work in a new tab at trinket.io/python3.
1.2) You will write your code under "main.py" in the editing tab, and your result will show up under the play tab.
2) Test out the trinket
2.1) Write the following in the trinket editing tab under "main.py":
print("hello world")
2.2) Run your code by pressing the play button at the top. In the result box, you should get hello world.
2.3) Go back to the editing tab and delete your code.
The result should be: ['alice', 'ben', 'cat', 'doug', 'frank']
7.5) Loop over the elements in the array:
names = ['ben','alice','evan','doug','cat']
names.append('frank')
names.remove('evan')
names.sort()
for i in names:
print(i+" is awesome!")
The result should be: alice is awesome!
ben is awesome!
cat is awesome!
doug is awesome!
frank is awesome!
7.6) Add an If block to the loop:
names = ['ben','alice','evan','doug','cat']
names.append('frank')
names.remove('evan')
names.sort()
for i in names:
if (i == "doug"):
print(i+" is awesome!")
else:
print(i+" is okay.")
The result should be: alice is okay.
ben is okay.
cat is okay.
doug is awesome!
frank is okay.
8) Measure word frequencies
8.1) Delete all of your code.
8.2) Import Counter a python library for counting:
from collections import Counter
8.3) Make a variable containing the entire text of the following article:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
8.4) Count the number of times "Google" occurs in the article:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
(print(article1.count("Google")))
The result should be: 9
8.5) Split the article into an array of individual words and get a word count:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
print(len(article1_array))
The result should be: 661
8.6) Find the 10 most common words in the article:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
print(article1_frequentWords)
The result should be: [('the', 36), ('a', 24), ('to', 15), ('in', 14), ('and', 14), ('of', 12), ('on', 9), ('that', 8), ('for', 8), ('is', 7)] This is an array of the ten most common words and the number of times they occur in the article.
Unfortunately, they're small words that aren't very useful.
8.7) Remove words smaller than 6 characters:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
for i in reversed(article1_array):
if (len(i) < 6):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
print(article1_frequentWords)
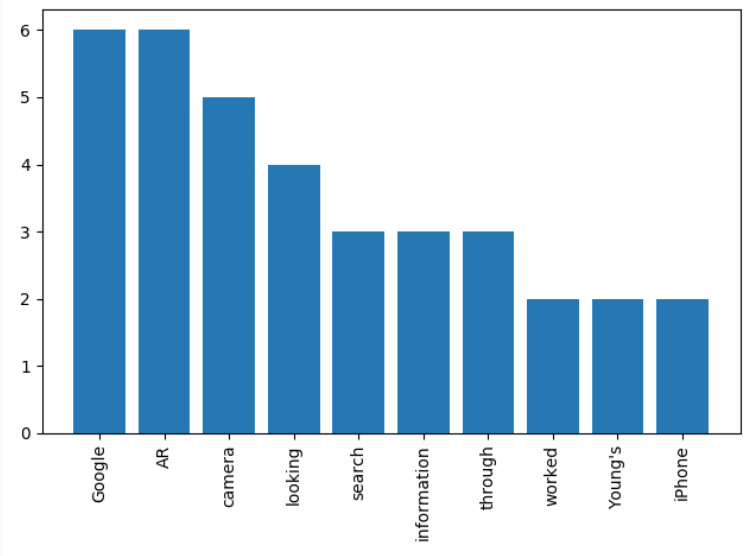
The result should be: [('Google', 6), ('camera', 5), ('looking', 4), ('search', 3), ('information', 3), ('through', 3), ('worked', 2), ("Young's", 2), ('iPhone', 2), ('within', 2)]
8.8) Keep small words that are important, like "AR":
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
print(article1_frequentWords)
The result should be: [('Google', 6), ('camera', 5), ('looking', 4), ('search', 3), ('information', 3), ('through', 3), ('worked', 2), ("Young's", 2), ('iPhone', 2), ('within', 2)]
Note that when we originally counted "Google" using article1.count("Google"), we found 9.
And now, using most_common(), we are only finding 6.
That's because split() makes an array of strings separated by a space, so when we use count("Google") on the array we created using split(), it will only find " Google " and not "Google." or "Google,".
As part of cleaning your data, you will probably want to remove unnecessary characters, like punctuation.
You may also want to convert all text to lowercase using lower().
9) Add a second article for comparison
9.1) Add the following article as a variable:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
article2 = "Google is adding 3D augmented reality models to its search results — so you can check out a pair of shoes in the ‘real world’ while you’re shopping online or put an animated shark in your living room. The company showed off the technology at its I/O keynote, although we still don’t know how many searches will end up delivering AR results. At I/O, Google offered a few different examples of how its AR search options might work. If you search for musculature, for instance, you can get a model of human muscles — which you can either examine as an ordinary 3D object on your screen or overlay on a camera feed, letting you ‘see’ the object in the real world. If you’re looking at shopping results, you can preview a piece of clothing with your existing wardrobe. According to Cnet, 3D AR objects will start showing up in search results later this year, and developers can add support for their own objects by adding ‘just a few lines of code.’ It’s apparently already working with NASA, New Balance, Samsung, Target, Volvo, and other groups to add support for their 3D models. Google has been offering augmented reality tools for a couple of years now. It unveiled its Android ARCore platform in 2017, and it’s launched tools like the whimsical Playground system, which lets people place augmented reality stickers called Playmoji — including characters from The Avengers and Detective Pikachu — into their camera feed. Google also recently began testing turn-by-turn augmented reality directions for Google Maps, a feature it announced at last year’s I/O conference. And apps like Wayfair have let people use augmented reality to preview furniture. This is all part of a larger arms race toward sophisticated phone-based augmented reality: Facebook, for instance, announced an expansion of its Spark AR platform at last week’s F8 conference. Search AR seems like something that will be more fun than useful in many cases — but options like AR shopping could turn out to be genuinely helpful, and developers could end up finding new and surprising uses as the tech rolls out."
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
print(article1_frequentWords)
9.2) For each of the 10 most common words in article1, see how many times it occurs in article2:
from collections import Counter
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
article2 = "Google is adding 3D augmented reality models to its search results — so you can check out a pair of shoes in the ‘real world’ while you’re shopping online or put an animated shark in your living room. The company showed off the technology at its I/O keynote, although we still don’t know how many searches will end up delivering AR results. At I/O, Google offered a few different examples of how its AR search options might work. If you search for musculature, for instance, you can get a model of human muscles — which you can either examine as an ordinary 3D object on your screen or overlay on a camera feed, letting you ‘see’ the object in the real world. If you’re looking at shopping results, you can preview a piece of clothing with your existing wardrobe. According to Cnet, 3D AR objects will start showing up in search results later this year, and developers can add support for their own objects by adding ‘just a few lines of code.’ It’s apparently already working with NASA, New Balance, Samsung, Target, Volvo, and other groups to add support for their 3D models. Google has been offering augmented reality tools for a couple of years now. It unveiled its Android ARCore platform in 2017, and it’s launched tools like the whimsical Playground system, which lets people place augmented reality stickers called Playmoji — including characters from The Avengers and Detective Pikachu — into their camera feed. Google also recently began testing turn-by-turn augmented reality directions for Google Maps, a feature it announced at last year’s I/O conference. And apps like Wayfair have let people use augmented reality to preview furniture. This is all part of a larger arms race toward sophisticated phone-based augmented reality: Facebook, for instance, announced an expansion of its Spark AR platform at last week’s F8 conference. Search AR seems like something that will be more fun than useful in many cases — but options like AR shopping could turn out to be genuinely helpful, and developers could end up finding new and surprising uses as the tech rolls out."
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
print(article1_frequentWords)
for i in article1_frequentWords:
print(i + ": " + str(article2.count(i)))
10.1) Import numpy and pyplot, python libraries for math and plotting:
from collections import Counter
import numpy as np
from matplotlib import pyplot as plt
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
article2 = "Google is adding 3D augmented reality models to its search results — so you can check out a pair of shoes in the ‘real world’ while you’re shopping online or put an animated shark in your living room. The company showed off the technology at its I/O keynote, although we still don’t know how many searches will end up delivering AR results. At I/O, Google offered a few different examples of how its AR search options might work. If you search for musculature, for instance, you can get a model of human muscles — which you can either examine as an ordinary 3D object on your screen or overlay on a camera feed, letting you ‘see’ the object in the real world. If you’re looking at shopping results, you can preview a piece of clothing with your existing wardrobe. According to Cnet, 3D AR objects will start showing up in search results later this year, and developers can add support for their own objects by adding ‘just a few lines of code.’ It’s apparently already working with NASA, New Balance, Samsung, Target, Volvo, and other groups to add support for their 3D models. Google has been offering augmented reality tools for a couple of years now. It unveiled its Android ARCore platform in 2017, and it’s launched tools like the whimsical Playground system, which lets people place augmented reality stickers called Playmoji — including characters from The Avengers and Detective Pikachu — into their camera feed. Google also recently began testing turn-by-turn augmented reality directions for Google Maps, a feature it announced at last year’s I/O conference. And apps like Wayfair have let people use augmented reality to preview furniture. This is all part of a larger arms race toward sophisticated phone-based augmented reality: Facebook, for instance, announced an expansion of its Spark AR platform at last week’s F8 conference. Search AR seems like something that will be more fun than useful in many cases — but options like AR shopping could turn out to be genuinely helpful, and developers could end up finding new and surprising uses as the tech rolls out."
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
print(article1_frequentWords)
for i in article1_frequentWords:
print(i + ": " + str(article2.count(i)))
10.2) Delete your two print statements, make blank arrays for x and y data, and fill the arrays with words and frequencies from Article 1:
from collections import Counter
import numpy as np
from matplotlib import pyplot as plt
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
article2 = "Google is adding 3D augmented reality models to its search results — so you can check out a pair of shoes in the ‘real world’ while you’re shopping online or put an animated shark in your living room. The company showed off the technology at its I/O keynote, although we still don’t know how many searches will end up delivering AR results. At I/O, Google offered a few different examples of how its AR search options might work. If you search for musculature, for instance, you can get a model of human muscles — which you can either examine as an ordinary 3D object on your screen or overlay on a camera feed, letting you ‘see’ the object in the real world. If you’re looking at shopping results, you can preview a piece of clothing with your existing wardrobe. According to Cnet, 3D AR objects will start showing up in search results later this year, and developers can add support for their own objects by adding ‘just a few lines of code.’ It’s apparently already working with NASA, New Balance, Samsung, Target, Volvo, and other groups to add support for their 3D models. Google has been offering augmented reality tools for a couple of years now. It unveiled its Android ARCore platform in 2017, and it’s launched tools like the whimsical Playground system, which lets people place augmented reality stickers called Playmoji — including characters from The Avengers and Detective Pikachu — into their camera feed. Google also recently began testing turn-by-turn augmented reality directions for Google Maps, a feature it announced at last year’s I/O conference. And apps like Wayfair have let people use augmented reality to preview furniture. This is all part of a larger arms race toward sophisticated phone-based augmented reality: Facebook, for instance, announced an expansion of its Spark AR platform at last week’s F8 conference. Search AR seems like something that will be more fun than useful in many cases — but options like AR shopping could turn out to be genuinely helpful, and developers could end up finding new and surprising uses as the tech rolls out."
data_x = []
data_y = []
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
for i in article1_frequentWords:
data_x.append(i[0])
data_y.append(i[1])
10.3) Chart your words and frequencies for Article 1:
from collections import Counter
import numpy as np
from matplotlib import pyplot as plt
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
article2 = "Google is adding 3D augmented reality models to its search results — so you can check out a pair of shoes in the ‘real world’ while you’re shopping online or put an animated shark in your living room. The company showed off the technology at its I/O keynote, although we still don’t know how many searches will end up delivering AR results. At I/O, Google offered a few different examples of how its AR search options might work. If you search for musculature, for instance, you can get a model of human muscles — which you can either examine as an ordinary 3D object on your screen or overlay on a camera feed, letting you ‘see’ the object in the real world. If you’re looking at shopping results, you can preview a piece of clothing with your existing wardrobe. According to Cnet, 3D AR objects will start showing up in search results later this year, and developers can add support for their own objects by adding ‘just a few lines of code.’ It’s apparently already working with NASA, New Balance, Samsung, Target, Volvo, and other groups to add support for their 3D models. Google has been offering augmented reality tools for a couple of years now. It unveiled its Android ARCore platform in 2017, and it’s launched tools like the whimsical Playground system, which lets people place augmented reality stickers called Playmoji — including characters from The Avengers and Detective Pikachu — into their camera feed. Google also recently began testing turn-by-turn augmented reality directions for Google Maps, a feature it announced at last year’s I/O conference. And apps like Wayfair have let people use augmented reality to preview furniture. This is all part of a larger arms race toward sophisticated phone-based augmented reality: Facebook, for instance, announced an expansion of its Spark AR platform at last week’s F8 conference. Search AR seems like something that will be more fun than useful in many cases — but options like AR shopping could turn out to be genuinely helpful, and developers could end up finding new and surprising uses as the tech rolls out."
data_x = []
data_y = []
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
for i in article1_frequentWords:
data_x.append(i[0])
data_y.append(i[1])
x_pos = np.arange(len(data_x))
plt.bar(x_pos,data_y)
plt.xticks(x_pos, data_x, rotation='vertical')
plt.tight_layout()
plt.show()
The result should look like this:
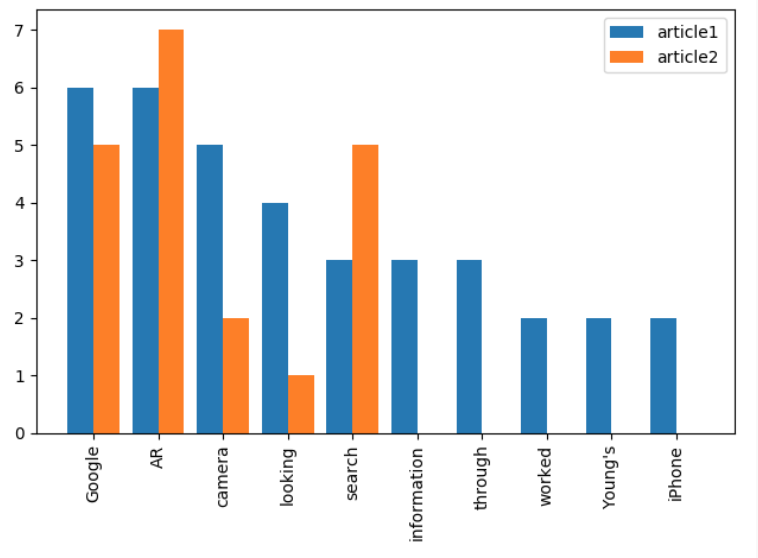
10.4) Add frequency data for the second article and a legend:
from collections import Counter
import numpy as np
from matplotlib import pyplot as plt
article1 = "Did you know that the painter Rockwell Kent, whose splendorous Afternoon on the Sea, Monhegan hangs in San Francisco's de Young Museum, worked on murals and advertisements for General Electric and Rolls-Royce? I did not, until I visited Gallery 29 on a recent Tuesday afternoon, phone in hand. Because the de Young's curators worked with Google to turn some of the informational placards that hang next to paintings into virtual launchpads, any placard that includes an icon for Google Lens—the name of the company's visual search software—is now a cue. Point the camera at the icon and a search result pops up, giving you more information about the work. (You can access Google Lens on the iPhone within the Google search app for iOS or within the native camera app on Android phones.) The de Young's augmented-reality add-ons extend beyond the informational. Aim your camera at a dot drawing of a bee in the Osher Sculpture Garden and a quirky video created by artist Ana Prvacki plays—she attempts to pollinate flowers herself with a bizarrely decorated gardening glove. It wasn't so long ago that many museums banned photo-taking. And smartphones and tablets were disapproved of in classrooms. But technology is winning, and the institutions of learning and discovery are embracing screens. AR, with its ability to layer digital information on top of real-world objects, makes that learning more engaging. Of course, these ARtistic addenda don't pop out in the space in front of you; they're not volumetric, to borrow a term from VR. They appear as boring, flat web pages in your phone's browser. Using Google Lens in its current form in a museum, I discovered, requires a lot of looking up, looking down, looking up, looking down. AR isn't superimposing information atop the painting yet. Then again, Lens isn't just for museums; you can use it anywhere. Google's AR spans maps, menus, and foreign languages. And Google's object-recognition technology is so advanced, the thing you're scanning doesn't need a tag or QR code—it is the QR code. Your camera simply ingests the image and Google scans its own database to identify it. Apple, loath to be outdone by Google, has been hyping AR capabilities via the iPhone and iPad, though not directly in its camera. Instead, Apple has created ARKit, an augmented-reality platform for app makers who want to plug camera-powered intelligence into their own creations. The platform has turned into an early-stage playground for educational apps. Take Froggipedia, which lets teachers lead students through a frog dissection without having to explain the senseless death of the amphibian. Or Plantale, which allows a student to explore the vascular system of a plant by pointing their iPad camera at one. Katie Gardner, who teaches English as a second language at Knollwood Elementary in Salisbury, North Carolina, says her kindergarten students ‘just scream with excitement’ when they see their drawings come to life in the iPad app AR Makr. It takes a 2D drawing and renders it as a 3D object that can be placed in the physical world, as viewed through the iPad's camera. Gardner uses the app for story-retelling exercises: The kids listen to a tale like Sneezy the Snowman and then use AR Makr on their iPads to illustrate a snippet of the narrative. In the real classroom, there is nothing on the table in the corner. But when the kids point their iPads at the table, their creations appear on it. It's too early to say how well we learn things through augmented reality. AR lacks totality by definition—unlike VR, it enhances the real world but doesn't replace it—and it's hard to say what that means for memory retention, says Michael Tarr, a cognitive science researcher at Carnegie Mellon University. ‘There is a difference between the emotional and visceral responses that happen when something is experienced as a real event or thing and when something is experienced as a digital or pictorial implementation of a thing,’ he says."
article1_array = article1.split()
article2 = "Google is adding 3D augmented reality models to its search results — so you can check out a pair of shoes in the ‘real world’ while you’re shopping online or put an animated shark in your living room. The company showed off the technology at its I/O keynote, although we still don’t know how many searches will end up delivering AR results. At I/O, Google offered a few different examples of how its AR search options might work. If you search for musculature, for instance, you can get a model of human muscles — which you can either examine as an ordinary 3D object on your screen or overlay on a camera feed, letting you ‘see’ the object in the real world. If you’re looking at shopping results, you can preview a piece of clothing with your existing wardrobe. According to Cnet, 3D AR objects will start showing up in search results later this year, and developers can add support for their own objects by adding ‘just a few lines of code.’ It’s apparently already working with NASA, New Balance, Samsung, Target, Volvo, and other groups to add support for their 3D models. Google has been offering augmented reality tools for a couple of years now. It unveiled its Android ARCore platform in 2017, and it’s launched tools like the whimsical Playground system, which lets people place augmented reality stickers called Playmoji — including characters from The Avengers and Detective Pikachu — into their camera feed. Google also recently began testing turn-by-turn augmented reality directions for Google Maps, a feature it announced at last year’s I/O conference. And apps like Wayfair have let people use augmented reality to preview furniture. This is all part of a larger arms race toward sophisticated phone-based augmented reality: Facebook, for instance, announced an expansion of its Spark AR platform at last week’s F8 conference. Search AR seems like something that will be more fun than useful in many cases — but options like AR shopping could turn out to be genuinely helpful, and developers could end up finding new and surprising uses as the tech rolls out."
data_x = []
data_y = []
data_y2 = []
for i in reversed(article1_array):
if ((len(i) < 6) & (i != "AR")):
article1_array.remove(i)
count = Counter(article1_array)
article1_frequentWords = count.most_common(10)
for i in article1_frequentWords:
data_x.append(i[0])
data_y.append(i[1])
data_y2.append(article2.count(i[0]))
x_pos = np.arange(len(data_x))
plt.bar(x_pos-.2, data_y, width=.4)
plt.bar(x_pos+.2, data_y2, width=.4)
plt.xticks(x_pos, data_x, rotation='vertical')
plt.tight_layout()
plt.legend(labels=['article1','article2'])
plt.show()
The result should look like this:
You learned how to do some basic text analysis using Python!
To learn more about Python text analysis, check out
this article on reading and writing text files,
Natural Language Tool Kit, a platform for more complex text analysis;
and also try using Jupyter Notebooks, which provide more functionality than Trinket.